
How to Build an Enterprise RAG System: A Comprehensive Guide
Introduction
Technologies and Dependencies
System Architecture
Enterprise RAG Architecture Best Practices
Document Processing Implementation
Vector Database Integration
Retrieval Augmented Generation Implementation
Prompt Engineering for Enterprise RAG Systems
API Development
Advanced Implementation Techniques
Building an Enterprise RAG System That Works in Production
How ASSIST Software Builds Enterprise RAG Systems
Frequently Asked Questions
Introduction
Companies today face a big challenge: they have too much digital information to handle effectively. They need tools that can store and find information, understand it, and give useful answers. This is where Retrieval Augmented Generation (RAG) systems come in. Enterprise RAG systems combine the power of modern Large Language Models (LLMs) with smart document processing to solve these problems.
Older document systems often struggle to understand context, rank information by importance, and give accurate answers. This leads to slow searches and unhappy users. Enterprise RAG systems fix these problems by delivering more accurate responses, reducing Artificial Intelligence mistakes, and minimizing processing costs. When you set up an enterprise RAG system, you get tools that can handle many document types, search through them quickly, and scale easily as you add more information.
System Overview
Our Retrieval Augmented Generation system implementation provides:
- Multi-format document processing;
- Efficient vector-based similarity search;
- Scalable API interface.
Technologies and Dependencies
Before diving into the implementation, let's look at the main technologies we used to build this Retrieval Augmented Generation (RAG) system. This will help you set up the right environment.
Programming Language: Python version 3.9 or higher is needed to run this system. We specifically tested it with Python 3.9.7, but it should also work with newer versions. Python 3.9 was selected for its stability and seamless integration with all our dependencies.
Main Libraries:
- FastAPI (0.68.0): For building our API endpoints
- Sentence-Transformers (2.2.2): For creating text embeddings
- FAISS-cpu (1.7.2): Handles our vector searches
- Pandas (1.3.3): For data processing
- PyPDF2 (2.10.5): For reading PDF files
- python-docx (0.8.11): For processing Word documents
- openpyxl (3.0.9): For Excel file handling
AI Models:
Storage:
All these versions work well together. If you use newer versions, you might need to adjust some code. We recommend starting with these exact versions to make sure everything works as shown in the examples.
System Architecture
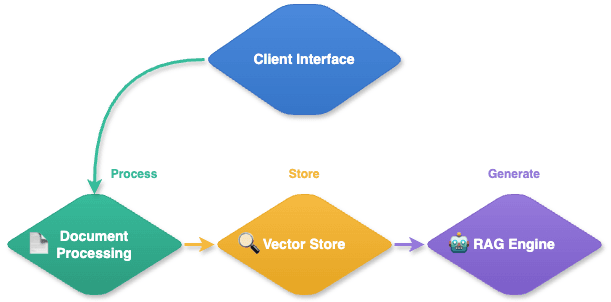
A good enterprise RAG system is built with four main parts that work together. First, there's the Document Processor, which handles incoming documents. It reads different types of files and extracts the text from them. Whether you're working with simple text files or complex documents with images, the Document Processor ensures everything is handled correctly.
The Vector Store turns document content into number patterns (vectors) that computers can easily compare. This particularly matters because searching through documents word by word gets very slow as you add more content - imagine searching through 100,000 documents versus just 100. Instead of scanning each document individually, the system uses vector comparisons to quickly find relevant content, like a smart index in a big library.
Enterprise RAG Architecture Best Practices
The RAG Engine is the manager of the whole system. It decides what information to pull out when someone asks a question and ensures the answers are accurate and relevant. By balancing speed and quality, it delivers precise answers without unnecessary delays.
Example of Core Architectural Principles
class RAGArchitecture: def __init__(self): self.document_processor = DocumentProcessor() self.vector_store = VectorStore() self.llm_engine = LLMEngine() self.api_layer = APILayer() def process_query(self, query: str) -> Dict[str, Any]: """ Demonstrates the flow of data through system components """ # Document processing docs = self.document_processor.get_relevant_docs(query) # Vector search context = self.vector_store.find_similar(docs) # Response generation response = self.llm_engine.generate_response(query, context) # API formatting return self.api_layer.format_response(response)
Document Processing Implementation
Processing documents in an enterprise RAG system requires smartly handling different file types. The system uses special tools for each kind of file, whether it's a PDF, Word document, or Excel spreadsheet. This makes sure we get good-quality text from any file type.
For PDFs, the system tries two approaches. First, it tries to get the text directly from the PDF. If that doesn't work well (like with scanned documents), it uses another method that can read text from images using Optical Character Recognition (OCR). This makes sure we can handle any kind of PDF.
When dealing with Word documents, the system keeps track of important formatting like headers and bold text. This helps it understand which parts of the text are more important than others.
For Excel files, the system analyzes the structure of rows and columns to understand how data is organized. This helps it make sense of numbers and text in spreadsheets while keeping track of how they're related to each other.
Format Handlers
class DocumentProcessor: """ A class that handles reading and processing multiple document formats. """ def __init__(self): self.handlers = { 'pdf': PDFHandler(), 'docx': DocxHandler(), 'xlsx': ExcelHandler() } def process_document(self, file_path: str) -> Dict[str, str]: """Process document with automatic format detection""" file_type = self._detect_file_type(file_path) handler = self.handlers.get(file_type) if not handler: raise UnsupportedFormatError(f"No handler for {file_type}") return handler.process(file_path)
Format-Specific Handlers
class PDFHandler: """Handles PDF document processing with OCR capabilities""" def process(self, file_path: str) -> str: try: # Try direct text extraction first text = self._extract_text(file_path) if not text.strip(): # Fallback to OCR if no text found text = self._perform_ocr(file_path) return text except Exception as e: logger.error(f"PDF processing error: {str(e)}") raise class ExcelHandler: """Processes Excel files with structured data extraction""" def process(self, file_path: str) -> str: df = pd.read_excel(file_path) return self._format_dataframe(df)
Vector Database Integration
The Vector Store is what makes searching through documents fast and smart. Instead of just looking for matching words, it understands the meaning of the text. This means it can find relevant information even when the words aren't the same.
Think of it like this: when you say "automobile," "vehicle," or "car," you're talking about the same thing. The Vector Store understands these connections. It turns document content into special patterns that capture meaning, making it easy to find related information quickly.
The search system is built to be both fast and accurate. It uses clever shortcuts to search quickly through lots of documents while still finding the right information. This means users get good answers fast, even when searching through many documents.
Understanding VectorStore and Embeddings
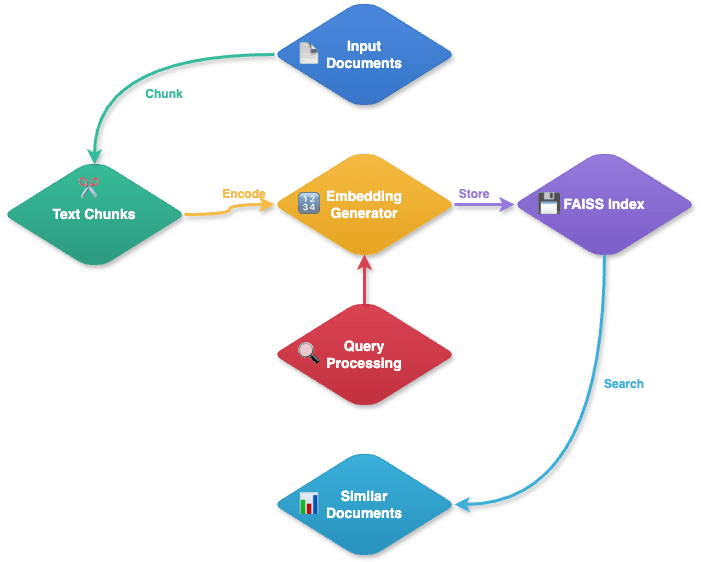
Document Processing Flow:
- Document Ingestion
- Embedding Creation
- Uses SentenceTransformer to process each content section;
- Creates unique numerical embeddings;
- Maintains mathematical representation of text meaning;
- Storage Management
- Stores embeddings in FAISS index;
- Maintains relationships between:
- Embeddings;
- Original documents;
- Specific content sections.
Query Processing Flow:
- Query Transformation
- Converts the user question into embeddings;
- Uses the same SentenceTransformer process as documents.
- Similarity Search
- Searches FAISS index for similar embeddings;
- Compares query embedding with stored document embeddings;
- Identifies the most relevant matches.
- Result Retrieval
- Fetches original content sections;
- Returns documents with the most similar embeddings.
Embedding Generation
class VectorStore: """Manages document embeddings and similarity search""" def __init__(self, model_name: str = 'sentence-transformers/all-MiniLM-L6-v2'): self.encoder = SentenceTransformer(model_name) self.index = faiss.IndexFlatL2(self.encoder.get_sentence_embedding_dimension()) def add_document(self, document: Dict[str, str]): """Add document to vector store""" embedding = self._encode_text(document['content']) self.index.add(np.array([embedding])) def _encode_text(self, text: str) -> np.ndarray: """Generate embedding for text""" return self.encoder.encode(text)
Search Optimization
class OptimizedSearch: """Implements optimized search strategies""" def search(self, query: str, top_k: int = 5) -> List[Dict]: query_vector = self._encode_query(query) # Perform approximate nearest neighbor search distances, indices = self.index.search( np.array([query_vector]), top_k ) # Post-process results return self._process_results(distances[0], indices[0])
Retrieval Augmented Generation Implementation
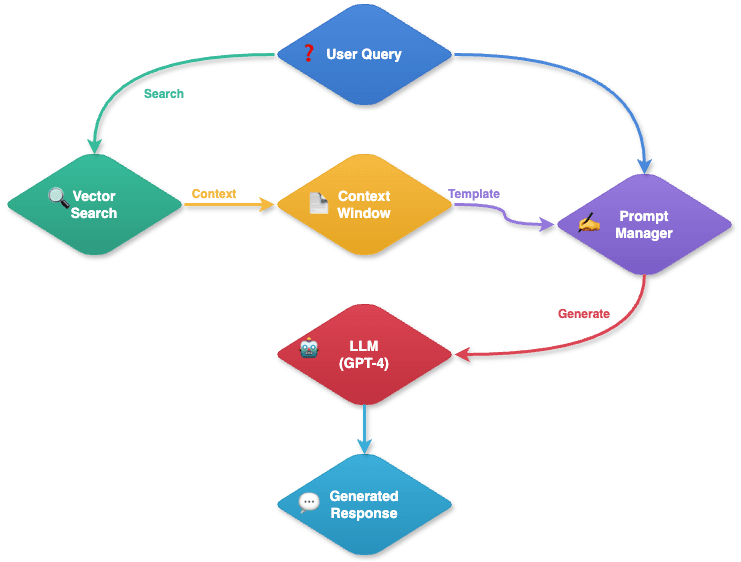
The enterprise RAG system works like a smart research assistant. When someone asks a question, it gets to work:
- It looks through documents to find relevant information (like searching through a library);
- It picks out the most important parts (like highlighting key passages in a book);
- It uses this information to create a clear, accurate answer (like writing a summary).
The system is designed to efficiently handle a wide range of questions. If information is spread across multiple documents, it can pull everything together to give a complete answer. It's like having someone who can read through many books quickly and give you a good summary of what they found.
Core Components
class RAGSystem: """Orchestrates document retrieval and response generation""" def __init__(self, vector_store: VectorStore, llm_client: LLMClient): self.vector_store = vector_store self.llm_client = llm_client self.prompt_manager = PromptManager() def generate_response(self, query: str) -> Dict[str, Any]: """Generate contextual responses using retrieved documents""" # Retrieve relevant documents relevant_docs = self.vector_store.search(query) # Prepare context context = self._prepare_context(relevant_docs) # Generate prompt prompt = self.prompt_manager.create_prompt(query, context) # Generate response return self._generate_answer(prompt)
Prompt Engineering for Enterprise RAG Systems
Think of prompt engineering as writing clear instructions for the LLM. Just as good directions help you reach your destination, the LLM needs clear instructions and prompts to give good answers.
Prompt Design Principles
Good prompts should be:
- Clear and specific;
- Properly structured;
- Context-aware;
- Error-handling capable.
Prompt Examples and Analysis
Basic Prompt (Not Recommended)
basic_prompt = f""" Answer the question based on the context. Context: {context} Question: {query} """
The basic example provided above is not recommended due to several important limitations:
- It doesn’t clearly guide the AI on how to use the information;
- The response format isn’t specified;
- There’s no instruction on handling potential issues;
- It doesn't check if the context actually relates to the question.
Optimised Prompt (Recommended)
class PromptManager: def generate_search_prompt(self, query: str, context: str) -> str: return f"""You are an AI assistant tasked with answering questions based on the provided context. Instructions: 1. Answer Format: - Use clear, concise language - Structure with appropriate markdown - Include relevant examples when available - Cite specific parts of the context 2. Response Requirements: - Only use information from the provided context - If information is not found, state "The provided context does not contain this information" - If the context is ambiguous, acknowledge the ambiguity - Maintain a professional tone Context: {context} Question: {query} Response Format: 1. Main Answer: [Concise answer to the question] 2. Supporting Details: [Relevant information from context] 3. Additional Context: [Any important caveats or clarifications] """
Prompt Optimization Strategies
Just like a good teacher adjusts their explanations to match students understanding, our system refines how it asks questions to the LLM. Prompt optimization is about making these questions clearer and more effective over time. The system watches how well its prompts perform and continuously improves them based on what it learns.
For example, if users often need clarification about technical terms, the system will learn to add simple explanations in its prompts. If responses are too general, it refines the prompts to request more specific details.
class PromptOptimizer: """Optimizes prompts for better response quality""" def optimize_prompt(self, base_prompt: str, metrics: Dict[str, float]) -> str: """Optimize prompt based on performance metrics""" optimized = base_prompt # Enhance clarity if needed if metrics['clarity'] < 0.8: optimized = self._improve_clarity(optimized) # Add structure if missing if metrics['structure'] < 0.7: optimized = self._add_structure(optimized) return optimized
API Development
The Retrieval Augmented Generation (RAG) system is designed to be simple to use. You only need two main endpoints to work with it: one for adding documents to the system, and another for asking questions about those documents. Think of it like a library desk - one place where you drop off books (upload documents), and another where you ask questions to get information. This simple setup makes it easy to connect the system to your existing applications.
Endpoint Design
from fastapi import FastAPI, File, UploadFile, HTTPException app = FastAPI(title="Enterprise RAG System") @app.post("/documents") async def upload_document(file: UploadFile): """Upload and process a new document""" try: result = await process_upload(file) return {"status": "success", "document_id": result.id} except Exception as e: raise HTTPException(status_code=400, detail=str(e)) @app.post("/query") async def query_system(query: QueryRequest): """Query the RAG system""" try: response = await rag_system.generate_response(query.text) return response except Exception as e: raise HTTPException(status_code=500, detail=str(e))
Advanced Implementation Techniques
The system works like a smart library. It remembers where important information is stored, just like knowing where you put your favorite books. When you search for something, it first checks these locations instead of looking through every document. This makes finding information quick and easy, even when you have lots of documents.
Hybrid Search
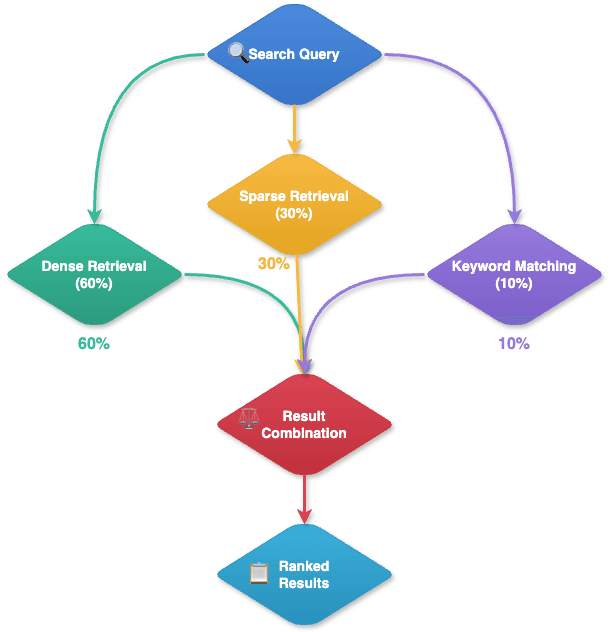
Our system uses three different ways to search through documents, combining them to get the best results. Think of it like using different methods to find a book in a library.
The main method, Dense Retrieval, handles 60% of the search work. It's like having a librarian who understands what you mean, not just what you say. For example, if you ask about "cars that run on electricity," it will find documents about "electric vehicles" even though the words are different. This method is best when you need to find information that might be expressed in different ways.
The second method, Sparse Retrieval, handles 30% of the search. This is like looking for specific words and seeing how often they appear in documents. It's particularly good at finding documents where exact terms are important, like technical documents or specific product names. For instance, if you're looking for documents about "Python programming," it will find texts that frequently mention these exact words.
The last method, Keyword matching, handles 10% of the search. This is the simplest approach, like looking at labels on file folders. It checks document titles, tags, and basic properties. While it's not as smart as the other methods, it's fast and useful for finding documents with clear labels or categories.
We use all three methods together because each has its strengths:
- Dense Retrieval is best for understanding meaning and context;
- Sparse Retrieval is great for finding specific technical terms;
- Keyword matching is fast and good for basic categorized searches.
This combined approach means we can find relevant information even when documents use different words to describe the same thing while still being able to quickly match exact terms when needed.
class HybridSearch: """Combines multiple search strategies""" def search(self, query: str) -> List[Dict]: # Vector search results vector_results = self.vector_store.search(query) # Keyword search results keyword_results = self.keyword_search.search(query) # Combine and rank results return self._combine_results(vector_results, keyword_results)
Performance Optimization
Think of our system as a smart assistant who learns from experience. When you ask a question, it first tries to remember if someone asked the same thing before, just like you might remember where you put your keys if you always keep them in the same place. If it's a new question, it looks through all the information to find the answer and then remembers it for next time. The system keeps information it uses often in an easy-to-reach place. In this way, it can help many people quickly without getting slow or confused.
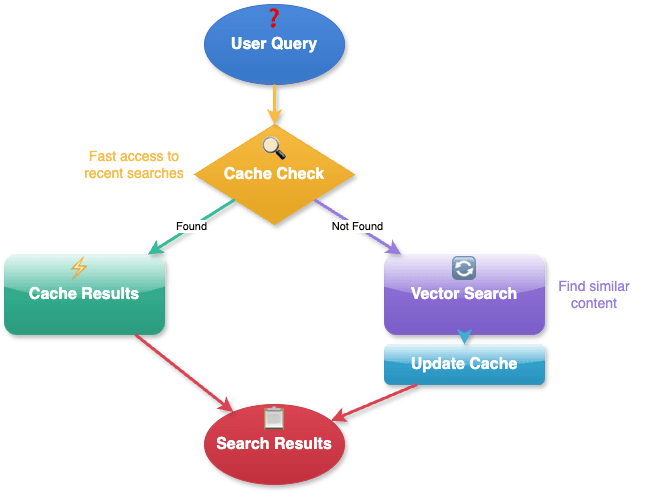
class PerformanceOptimizer: """Implements various optimization strategies""" def optimize_search(self, query: str) -> List[Dict]: # Cache check if cached := self.cache.get(query): return cached # Perform search results = self.search_engine.search(query) # Cache results self.cache.set(query, results) return results
Advanced Performance Optimization
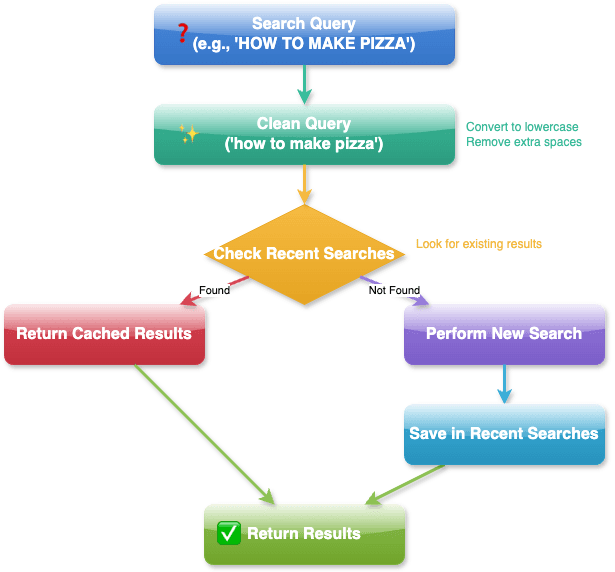
This approach focuses on intelligent caching and streamlined query processing. Our performance optimization flow consists of several key components working together to deliver fast, accurate results:
Query Processing and Optimization
When someone asks a question like "HOW TO MAKE PIZZA," the system first cleans up the question. It makes all letters lowercase, removes extra spaces, and ensures the question is written in a standard way. This is like ensuring everyone writes their questions the same way so they're easier to understand and answer.
The system then takes one of two paths. If it has seen the question before (we call this a "cache hit"), it quickly gives back the stored answer. This is much faster than searching through all the documents again. It's like the librarian immediately reaching for a book they know has the answer instead of searching through the whole library.
Building an Enterprise RAG System That Works in Production
An enterprise RAG system does more than speed up document search. It changes how organizations find and use the knowledge they already have. When you combine vector-based similarity search, multi-format document processing, and LLM-driven response generation the way we covered in this guide, you get a system that returns accurate, context-aware answers at scale, without the hallucinations and retrieval failures that make simpler approaches fall apart in real environments.
The technical choices at each layer, from embedding model selection and FAISS indexing to prompt engineering and API design, have a direct impact on whether the system becomes a genuine operational asset or an expensive prototype. Getting those decisions right from the start matters.
Enterprise RAG systems are changing how companies handle information, and as the technology keeps improving, the organizations that build and maintain them well will have a clear advantage in how fast and accurately they can put their own knowledge to work.
How ASSIST Software Builds Enterprise RAG Systems
Wise Mate, ASSIST Software's enterprise knowledge retrieval platform, was built on the same architecture described in this guide: multi-format ingestion, optimized vector search, and production-ready API infrastructure built to handle the scale and complexity that real enterprise document environments throw at it.
If you are working on a RAG system and want to talk through the architecture or need a team to build it, ASSIST Software's AI/ML and Data Engineering team has done this across multiple production deployments. Explore our full range of AI & ML software development services or reach out directly at hello@assist.ro.
Frequently Asked Questions
What are the most effective document storage solutions for optimizing RAG performance?
Vector databases like FAISS are the standard choice for enterprise RAG, converting document content into numerical embeddings that enable fast semantic search across large document sets. The right solution depends on scale, query volume, and whether the system needs to understand meaning across varied terminology or match exact terms, factors that determine whether dense retrieval, sparse retrieval, or a hybrid approach delivers the best results.
How does enterprise RAG architecture differ from traditional document search?
Traditional search matches keywords. Enterprise RAG retrieves relevant context semantically and uses a large language model to generate accurate, synthesized answers. A well-built architecture integrates four components: a document processor, a vector store, a RAG engine, and an API layer.
What are enterprise RAG implementation best practices?
Reliable implementations combine multi-format document processing, optimized prompt engineering, and hybrid search strategies that mix dense retrieval, sparse retrieval, and keyword matching. Caching, query normalization, and clean API design are essential for performance and integration at scale.
How does ASSIST Software's AI and ML engineering team support enterprise RAG development?
ASSIST Software builds production-ready RAG systems using Python-based document processing, vector database integration, and LLM orchestration. With delivered projects spanning NLP, intelligent automation, and predictive analytics, the team brings the engineering depth to take RAG implementations from prototype to reliable production deployment. Wise Mate is a concrete example of this in practice.



