
How to create your first schema in GraphQL
Date published: August 10, 2020
8 min read

1. What is GraphQL and why do we need it?
GraphQL is a query language, an intermediary that we need between the front-end application client and the backend data service. GraphQL is used to communicate with queries for reading actions and with mutations for writing actions.
When a client needs access to data from two database services at the same time, with GraphQL in the middle, the user only needs to communicate with one GraphQL layer and not with different services.
With a usual API call, you receive all fields. However, with GraphQL, you can get the specific fields that you need. For example, if you only want to get the firstName and jobTitle fields from an employee, you can make an API call so that you only get the information that you need.
The response will be a JSON Object and the answer will match with the request query. Every field in the query becomes a key in the answer’s Object.
GraphQL operations are written in documents on the client-side and then they are used in the interface of GraphQL’s server. The most common protocol for GraphQL is HTTP. A GraphQL document can contain one or more operations. If it contains more than one operation, it will also have to tell the server what operation to execute from the list of operations defined in the document.
The purpose of a GraphQL runtime is to understand GraphQL documents and translate them for the other services in the server-side stack. GraphQL runtime can be added to any existing data service or multiple data services. The data services layer will prepare the data for the request and transfer it over to the GraphQL engine which puts it together and sends it to the client who asked for it.
2. GraphQL Query Language
The GraphQL Query Language is designed to be a flexible syntax that is easy to read and understand.
Queries can have names. For example, in Figure 1, the query name is TestQuery and it contains two types of fields:
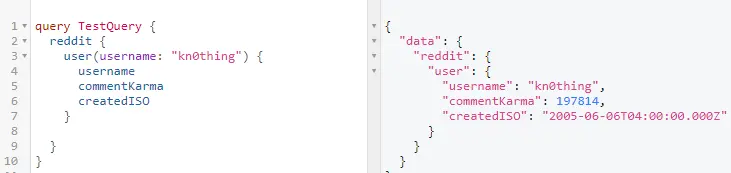
Figure 1 – TestQuery fields
- Scalar fields like: username, commentKarma and createdISO. These are the basic types in the GraphQL schema and they can represent integers, floats, strings or booleans.
- Complex fields like: reddit and user. Fields that represent objects have a custom type, for example, the user field belongs to the RedditUser type (see Figure 2).
Figure 2 – user field type
The RedditUser type represents an object that has some properties and each property has its own type (see Figure 3). Types are not only for fields, they are also for arguments.

Figure 3 – user objects’ properties
The query from Figure 1 works for a single user. Currently, the argument has a hard-coded value - “kn0thing” - but in our case, it can be replaced with a variable $currentUserName (see Figure 4).
The variable needs to have a type defined in TestQuery and specified to be a required string.
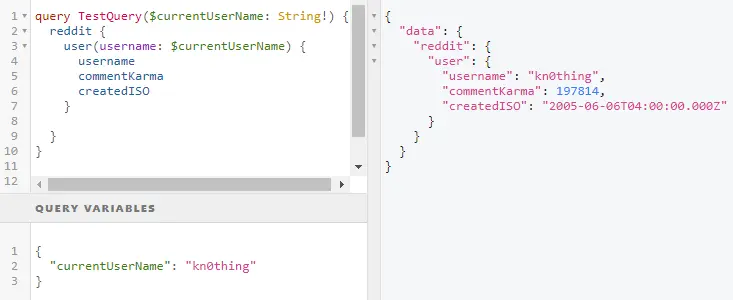
Figure 4 – User variable for query parameter
The behavior of the GraphQL server execution engine can be customized with directives. In Figure 5, the variable IncludeISO is defined in query variables and its value will be set to false. It is expected that the response will not include the createdISO field when this variable is set to false (see Figure 5).
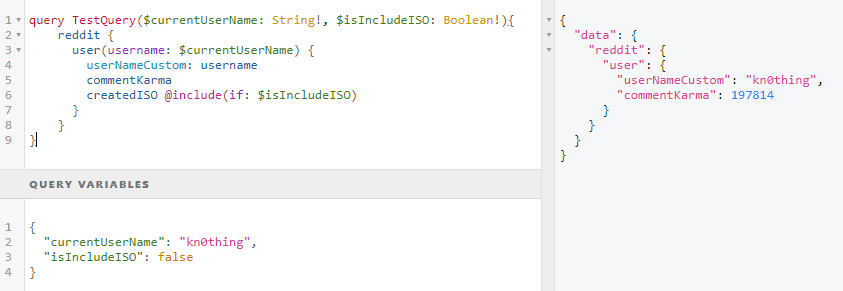
Figure 5 – Customise query using directives and aliases
Aliases are used to customize the appearance fields in the response. Instead of using username, you can use userNameCustom: ursername (see Figure 5).
To avoid repetition in GraphQL, you can use fragments. A fragment can be defined by using the fragment keyword, giving it a name and specifying which type this fragment can be used on. A fragment is a partial operation that can be reused in an operation. To use a fragment in an operation, you have to prefix its name with three dots (see Figure 6).
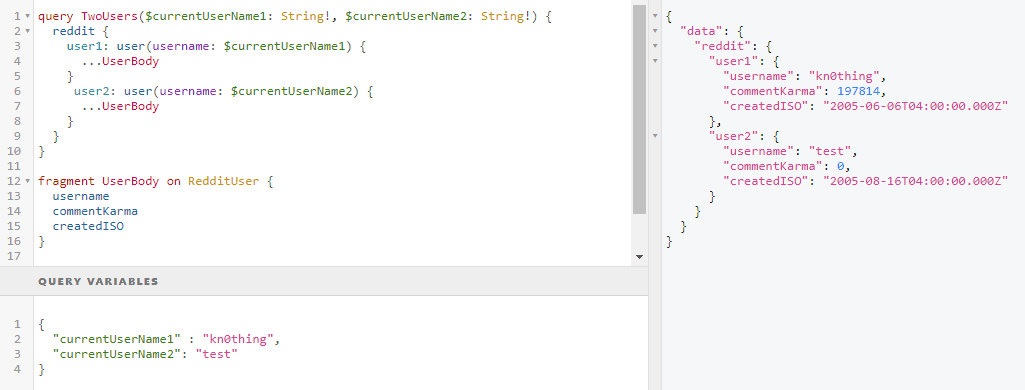
Figure 6 – Using fragments
Reading is not the only operation that clients can use to communicate with a server. Clients can also update the data with the help of GraphQL and for this, you have to write a mutation.
A mutation is similar to a GraphQL query but running a mutation will have some effect on the data. Every mutation has an input that the server uses to execute the mutation. Also, every mutation has an output that contains everything that was read after the mutation was executed.
In Figure 7, GraphQLHubMutationAPI is used for the mutation. This API contains one GraphQL mutation.
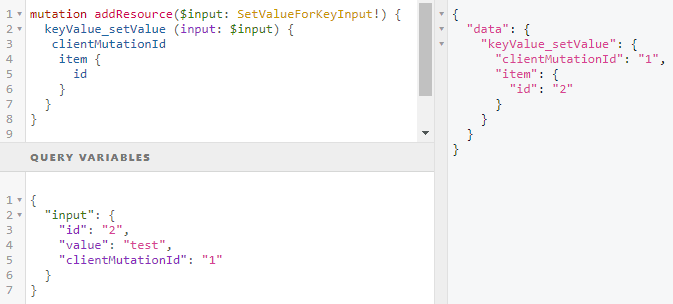
Figure 7 – Mutation
keyValue_setValue expects a single argument input that is of type SetValueForKeyInput (see Figure 8). This type has three required strings: id, value, and clientMutationId.
In the mutation payload, we read clientMutationId and the id from item.
Figure 8 – keyValue_setValue type
3. Create your first GraphQL Schema
Initialize a node project with the following command: npm init. Install the express app by running npm install express.
The next step is to run npm install graphQL express-graphql so that the express app can interact with GraphQL.
Under the root folder, create a file called app.js and inside it, require express. Then invoke the function to run the app on a specific port.
Also under the root folder, you have to create a folder named schema and inside the folder, create a file called schema.js and then in this file, require graphql. The variables GraphQLObjectType, GraphQLString, GraphQLSchema and GraphQLID are taken from the graphql package.
BookType is an object type that has different fields: id, name, author, reader. The id type is GraphQLID and the name and author type is GraphQLString. ReaderType and BookType are created in similar ways and ReaderType contains the following fields: id, name, age.
The reader property from BookType is used to associate a book to a reader. This property is an object and its type is ReaderType. In the resolve function, you will find which reader corresponds with the current book.
Usually, the data will be taken from the database or from an external service and this requires async action. The async function has been introduced to help solve problems with asynchronous code. By using the async function, the code works as if it were synchronous.
The property reader from BookType contains an async resolve. The testAsyncFunction function will be executed first and after the result is returned, the message from console.log will be displayed.
The schema file has the following responsibilities: to define types, relationships between types and the root query. When a developer creates a query with a book, the type that is being looked for is BookType and the argument that is expected to be sent with the query is an id. The resolve function contains code that will get any data that you need. In schema.js, create a GraphQLSchema that will be used in the app.js file.
schema.js
const graphql = require("graphql"); const getBooks = require("./../../data/books"); const getReaders = require("./../../data/readers"); const { GraphQLObjectType, GraphQLString, GraphQLSchema, GraphQLID, GraphQLInt, GraphQLList } = graphql; const books = getBooks; const readers = getReaders; const BookType = new GraphQLObjectType({ name: "Book", fields: () => ({ id: { type: GraphQLID }, name: { type: GraphQLString }, author: { type: GraphQLString }, reader: { type: ReaderType, async resolve(parent, args) { const queryResult = await testAsyncFunction(parent); console.log("Displayed after return"); return queryResult; } } }) }); async function testAsyncFunction(parent) { return readers.find(reader => reader.id === parent.readerId); } const ReaderType = new GraphQLObjectType({ name: "Reader", fields: () => ({ id: { type: GraphQLID }, name: { type: GraphQLString }, age: { type: GraphQLInt }, books: { type: new GraphQLList(BookType), resolve(parent, args) { return books.filter(book => book.readerId === parent.id); } } }) }); const RootQuery = new GraphQLObjectType({ name: "RootQueryType", fields: { book: { type: BookType, args: { id: { type: GraphQLID } }, resolve(parent, args) { return books.find(book => book.id === args.id); } }, reader: { type: ReaderType, args: { id: { type: GraphQLID } }, resolve(parent, args) { return readers.find(reader => reader.id === args.id); } }, books: { type: new GraphQLList(BookType), resolve(parent, args) { return books; } }, readers: { type: new GraphQLList(ReaderType), resolve(parent, args) { return readers; } } }Running on port }); module.exports = new GraphQLSchema({ query: RootQuery });
app.js
const express = require("express"); const graphqlHTTPS = require("express-graphql"); const schema = require("./schema/schema"); const app = express(); app.use( "/graphql", graphqlHTTPS({ schema, graphiql: true }) ); app.listen(4000, () => { console.log("Running on port 4000"); });
The result of the query can be seen in Figure 9. As you can see, the book query receives an id and sends back details about the book (name and author) and details about the reader (name and age).
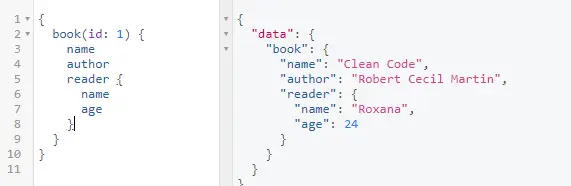
Figure 9 – Application result
4. Conclusion
GraphQL can be a good alternative to REST and there are many reasons to use it. By using REST, you will get the entire object entity whereas by using GraphQL, you will be able to only get the selected parts that you need.
Sometimes REST can be inefficient when it comes to making requests. For example, if you want to identify a reader entity by using an id and then get all the books using the reader’s id, with GraphQL this is possible with a single request whereas with REST, you would need two requests. GraphQL provides better solutions for the common problems faced developer when using REST APIs.
Sometimes REST can be inefficient when it comes to making requests. For example, if you want to identify a reader entity by using an id and then get all the books using the reader’s id, with GraphQL this is possible with a single request whereas with REST, you would need two requests. GraphQL provides better solutions for the common problems faced developer when using REST APIs.



