

How to Avoid Serverless Resource Limiting when Using GraphQL

Nowadays, Serverless based projects are being developed for multiple industries. Similarly, GraphQL is seeing an increase in popularity and usage as an alternative to REST APIs. Serverless framework limitations are hard to avoid. An example of one is the 200 resources limit for a project, and the limit of a 15-minute runtime for an Amazon Web Services (AWS) Lambda function. As a Serverless project can quickly reach these limitations, we propose a method that will alleviate this problem when using GraphQL.
The evolution of humanity places us in the Industry 4.0 era. The main characteristic of this period is that machines, sensors, and devices are interconnected into what is called the Internet of Things (IoT). This goal dictates increasing digitization and automation of everyday processes, which is possible through the development and use of new technologies. These technologies include the Serverless computing service launched by Amazon in November 2014 through AWS Lambda, followed by Microsoft Azure and Google Cloud functions, as well as several open-source projects, such as Apache OpenWhisk and Knative.
Serverless computing is the main enabler for Industry 4.0 processes. It consists of a set of microservices through which code is run in response to events. These microservices also help with the automatic management of computational resources needed to run the response code. Also known as functions-as-a-service (FaaS), Serverless computing allows developers to write short-running and stateless functions that can be triggered by different events generated from services, middleware, sensors, or users.
The Serverless service has many advantages for developers. As Scott Hanselman said: “Serverless Computer doesn’t really mean there’s no server. Serverless means there’s no server you need to worry about.” Eliminating server management activities saves developers time and allows them to focus on the logic of their applications. Using a Serverless framework is also cost-effective as payment is not required for storing the functions in the AWS servers; Payment is only needed for their execution. In addition, the Serverless framework helps in securing applications by managing server providers who may be considered more likely to keep their machines up to date.
GraphQL is a database query and manipulation language for Application Programming Interfaces (APIs). It was launched as an open-source project in 2015 by Facebook with the intent of being a modern alternative to the REST API architecture. Unlike REST, GraphQL allows requesting particularized data from the application.
As suggested in Fig. 1, the popularity of both the Serverless framework and GraphQL has increased over the past few years as more and more questions about these topics are being asked on various programming discussion forums, such as Stack Overflow and Reddit.
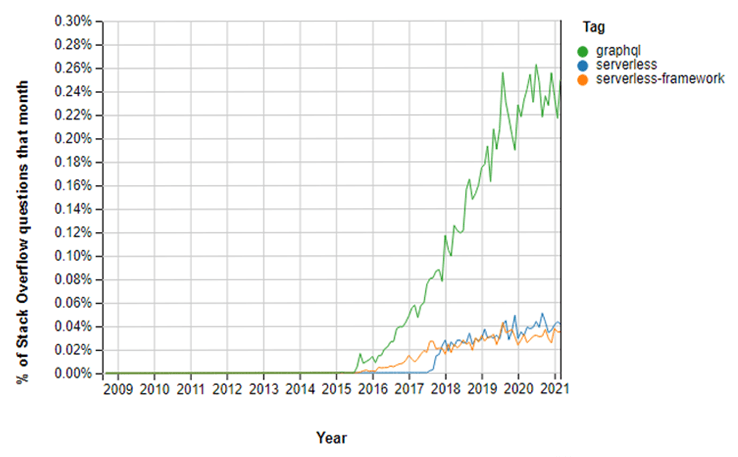
Fig. 1 – Increasing usage of the Serverless framework and GraphQL
Source: Stack Overflow
As these technologies are increasing in popularity, solving the problems involved in using them is becoming a more relevant issue. Of particular importance is the problem of not being allowed to use more than 200 resources on a Serverless project. This is a limit that is easily reachable by modern projects. This article aims to solve this problem for the Serverless paradigm in general and the Serverless framework from AWS in particular.
Working with the AWS Serverless Framework implies operating with some microservices. Some examples of microservices provided by AWS include Lambda functions, API Gateway, Cognito, DynamoDB, IAM, AppSync, and Amazon QLDB.
Each of these microservices has some limitations. For example, AWS Lambda functions are forcibly stopped when they run for more than 15 minutes or allocate more than the maximum memory of 10,240 MB. Usually, these restrictions are specified in the AWS Documentation for each microservice. Some of these thresholds can be increased (via code or UI options), whereas others can’t because they are constraints imposed by the entire AWS platform.
Some of the restrictions are applicable to the entire project. One such limitation is that a Serverless project cannot have more than 200 resources. It is easy to reach this limit. For example, let’s say a project consists of multiple DynamoDB tables, a Cognito User Pool, and a number of Lambda functions. To connect the Lambda functions with a front-end application, we might use API Gateway - as REST API calls - or GraphQL. When connecting Lambda functions with GraphQL using AppSync, a project needs a data source and a resolver for each function. Thus, each endpoint will add at least three new resources to the project. By adding a few such functions, a project can quickly reach the 200 resources threshold. Thus, to support larger projects, we propose a solution in the following sections.
Other limitations of the Serverless framework are narrow support for more programming languages, limited or no support for specialized computing platforms or hardware accelerators such as GPUs, I/O bottlenecks, and communication through slow storage.
DeBrie and Allardice suggested some solutions to solve the issue of being allowed to use at most 200 resources. These include the following:
- Breaking the project into different services (sub-projects) - Some microservices will generate by default different instances (a new domain for API Gateway, a new user pool for Cognito, etc.) for every sub-project. But it is also possible to configure these services to use the same instance in every sub-project.
- Using all the application logic in a single Lambda function - This approach leads to a very big file where all the logic is managed, but this is hard to maintain and further develop. It also violates some coding principles like KISS (Keep It Short and Simple) and SRP (Single Responsibility Principle).
- Using plugins to split the stacks - There are some plugins (serverless-nested-stack or serverless-plugin-split-stacks) that split the resources into different stacks, but these plugins are not easily customizable and you also might reach the 200 resources limit. This is a good solution overall, but it’s only temporary.
Splitting the project into different sub-projects seems to be the best solution in the long term. However, this doesn’t work when using GraphQL with the Serverless framework because of GraphQL’s architectural constraints.
Our project structure (front-end + back-end) is presented in Fig. 2.
We used the React framework on the front end. To connect with the back-end, we used AWS Amplify and Apollo Client.
On the back-end, we used Cognito to manage our application’s users. AWS AppSync facilitated the connection with the GraphQL language. The API Gateway was used for needed REST API calls. Because all endpoints that are built with AppSync require logged-in users, we also connected it with Cognito. All the application logic was managed by Lambda functions, which were also responsible for the needed operations on the DynamoDB database.
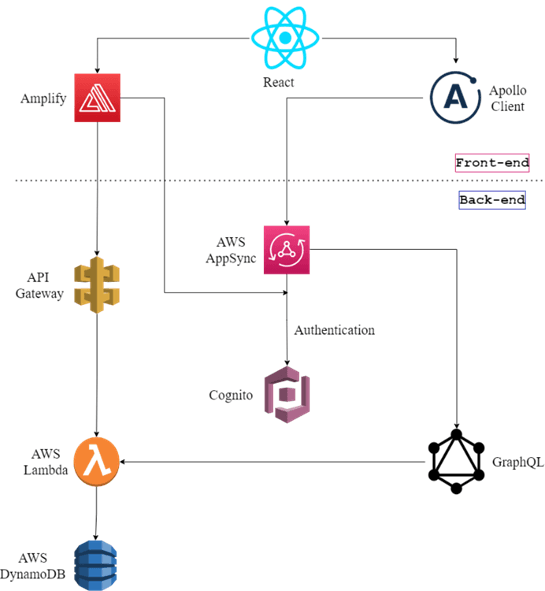
Fig. 2 - Project structure
Initially, we configured the project according to these suggestions, using serverless-appsync-plugin to connect with GraphQL functionalities. The configuration was similar to the one listed in Listing 1.
We defined a function updateUser with the handler specified by src/updateUser.handler. We granted access permission as a service account.
In the custom section, we specified the Serverless configuration for appsync. Of interest is the mappingTemplates section, where we defined a mapping between request and response data formats and GraphQL parameters.
functions:
updateUser:
handler: src/updateUser.handler
role: AppSyncLambdaServiceRole
custom:
accountID: #{AWS::AccountId}
appSync:
name: appsync-${provider_stage}-api
authenticationType: AMAZON_COGNITO_USER_POOLS
userPoolConfig:
awsRegion: ${provider_region}
defaultAction: ALLOW
userPoolId:
Ref: CognitoUserPool
mappingTemplates:
- dataSource: awsLambdaUpdateUser
type: Mutation
field: user
request: "request.txt"
response: "response.txt" Listing 1 - Initial code structure
When the serverless project reached the threshold of 200 resources, the first solution attempted was to use the serverless-plugin-split-stacks. However, this only worked temporarily (as we again reached the 200 resources limit).
The next approach was to split the project into some sub-projects. Since serverless-appsync-plugin cannot be configured to use the same instance of AppSync in different serverless projects, we exported the references of the functions in the sub-projects of the principal project. This allowed us to add GraphQL calls. An example of exporting a Lambda function from a Serverless sub-project is in Listing 2.
UpdateUserLambdaFunctionExport:
Value:
'Fn::GetAtt': [UpdateUserLambdaFunction, Arn]
Export:
Name: 'updateUser-${provider_stage}' Listing 2 - Exporting a Lambda function
With this export, the functions section of Listing 1 was replaced by the code in Listing 3, which specifies the function that is referenced and the service account role.
- type: AWS_LAMBDA
name: awsLambdaUpdateUser
description: 'LambdaUpdateUser'
config:
lambdaFunctionArn: { Fn::ImportValue: 'updateUser-${provider_stage}'}
serviceRoleArn: { Fn::GetAtt: [AppSyncServiceRole, Arn]} Listing 3- Importing a Lambda function
It is essential to mention that the import value must be the same as the name we exported.
This solution works because it allows moving many resources to one of the sub-projects and only referencing them in the main project.
However, as the application grows, more and more resources will be needed, and the 200 resources threshold will be reached again because multiple AppSync mapping templates and data sources will be needed in the main project. So, our solution is to split the AppSync resource while keeping the same API. This should work even if the functions are defined in different Serverless projects.
Instead of using the serverless-appsync-plugin plugin, we used the AppSync API with the AWS::AppSync::GraphQLApi resource. The API and the corresponding GraphQL schema were defined in a graphql.yml file as resources of the main project as shown in Listing 4.
GraphQLApi:
Type: AWS::AppSync::GraphQLApi
Properties:
AuthenticationType: AMAZON_COGNITO_USER_POOLS
UserPoolConfig:
AwsRegion: ${provider_region}
DefaultAction: ALLOW
UserPoolId:
Ref: CognitoUserPool
Name: appsync-graphql
SchemaTest:
Type: AWS::AppSync::GraphQLSchema
Properties:
ApiId: { Fn::GetAtt: [GraphQLApi, ApiId]}
Definition: "type User {
id: ID
userName: String
userEmail: String
}
type Mutation {
updateUser(id: ID!, userName: String, userEmail: String): User!
deleteUser(id: ID!): String!
}
type Query {
getUser(id: ID!): User!
}
schema {
query: Query
mutation: Mutation
}"
Outputs:
GraphQLApiId:
Value: { Fn::GetAtt: [GraphQLApi, ApiId] }
Export:
Name: "graphQLApiId" Listing 4 - GraphQL definition
The GraphQLApi section defines the API to be used in the application and the link that will be called from front-end.
The GraphQLSchema section contains the definition of each function. It should contain a query section that includes all the functions needed to get data, and a mutation section that includes all the functions that modify data. Each function must be defined, specifying the parameters list and the return value. Custom data types (for inputs and outputs) can be specified in this schema.
As can be seen in Listing 4, we also defined an output parameter, GraphQLApiId, which will be imported in the GraphQL definition for every project. It helps to use the same id across all sub-projects.
For each serverless project (the main project and the subprojects), we created a new file under the Resources section that contains the definitions of every function’s data source and resolver. These resources use the AppSync API id exported in the graphql.yml file. One example is shown in Listing 5.
UpdateUserDataSource:
Type: AWS::AppSync::DataSource
Properties:
ApiId: { 'Fn::ImportValue': 'graphQLApiId' }
Name: UpdateUser
Type: AWS_LAMBDA
LambdaConfig:
LambdaFunctionArn: {'Fn::GetAtt': [UpdateUserLambdaFunction, Arn]}
ServiceRoleArn: { 'Fn::ImportValue': 'appSyncServiceRole-${provider_stage}' }
UpdateUserResolver:
Type: AWS::AppSync::Resolver
Properties:
ApiId: { 'Fn::ImportValue': 'graphQLApiId' }
DataSourceName: UpdateUser
FieldName: updateUser
TypeName: Mutation
RequestMappingTemplate: "{
\"version\": \"2017-02-28\",
\"operation\": \"Invoke\",
\"payload\": {
\"field\": \"updateUser\",
\"arguments\": $utils.toJson($context.arguments),
\"handle\": $utils.toJson($context.identity)
}
}"
ResponseMappingTemplate: $util.toJson($context.result) Listing 5 - Data Source and Resolver definitions
For a function to work, it needs to be deployed in two different configurations because a GraphQL resolver cannot be deployed if the corresponding data source has not been previously deployed.
This solution scales so that the 200 resources threshold would not impact the application anymore. Whenever a project or a sub-project is close to this limit, we can easily split it into another sub-project. This is because the proposed solution resolves any issues stemming from splitting the AppSync resources.
In this article, we proposed a solution for one of the biggest limitations of the AWS Serverless framework. We hope that this article will give an answer to a problem that many developers face.
With this solution, any project based on one or both of the two increasingly used technologies (the Serverless framework and the GraphQL language) will never be blocked when reaching the 200 resources limit.
This solution will scale even when the Serverless framework is improved to support more resources. Larger projects can reach any improved limit.
We realized that current plugins, while enabling fast prototyping, are not very configurable and this results in issues when projects reach infrastructure limits. Since using plugins impedes creating scalable solutions, we recommend using native APIs for extensive projects.
For more blog posts about this topic, check out:



