




- 1. The Difference Between Managed and Unmanaged Code
- 2. How Managed and Unmanaged Code Run
- 3. Risks and Mitigation Strategies for Unmanaged Code
- 4. Performance Optimization in Managed and Unmanaged Code
- 5. Testing Strategies for Unmanaged Code
- 6. Frequently Asked Questions and Best Practices for Testing Managed and Unmanaged Code
- 7. Mastering the Balancing Act: Managed vs. Unmanaged Code

QA Engineer II at ASSIST
Read time: 9 minutes

1. The Difference Between Managed and Unmanaged Code
Managed and Unmanaged code are two distinct approaches in software development. The key difference is that while managed code runs within a runtime environment, providing automatic memory management and high-level abstractions, the unmanaged code runs directly on the hardware, giving the developer more control but requiring manual memory and pointers management.
2. How Managed and Unmanaged Code Run
2.1. Understanding Managed Code (with examples)
In managed code, programs run in a managed runtime environment, such as CLR in .NET. The code is compiled into an IL (intermediate language), and it is executed by the runtime, which handles tasks such as memory management, garbage collection, type safety, and exception handling.
Example: Consider a C# application running on the .NET framework. When the application is compiled, the C# source code is translated into IL bytecode. At runtime, the CLR JIT (Just-In-Time) compiler converts the IL bytecode into native machine code, which is executed by the underlying hardware. The CLR manages memory allocation, garbage collection, and other runtime services, allowing developers to focus on writing high-level code without worrying about low-level system interactions.
2.2 Understanding Unmanaged Code (with examples)
In contrast, the unmanaged code operates directly on hardware without using a runtime environment. These are typically low-level programming languages, such as C or C++, which are compiled into native machine code and executed by the CPU itself.
Example: Imagine a C++ application interacting with hardware devices or performing low-level system operations. In this scenario, the code is compiled into native machine code specific to the target hardware architecture. When executed, the CPU directly interprets and executes the machine instructions, allowing the application to interact with hardware components or perform system-level tasks with minimal overhead. However, developers must manually handle memory management and other system interactions, which can introduce complexities and potential risks.
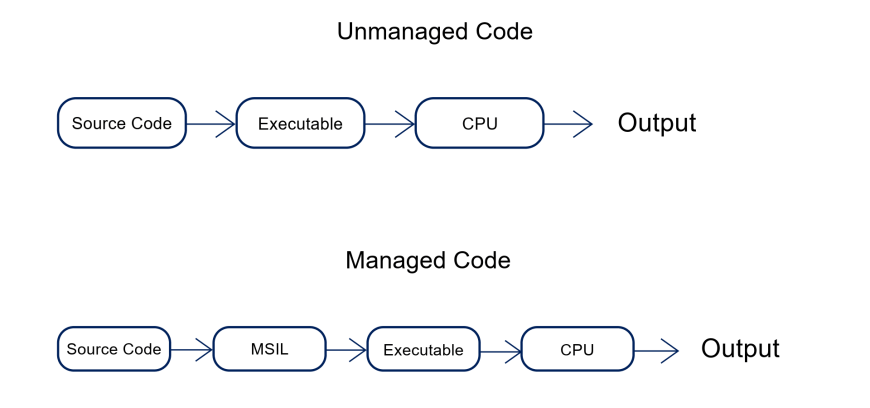
Image 1: Difference between Managed and Unmanaged Code
3. Risks and Mitigation Strategies for Unmanaged Code
While inherently challenging, unmanaged code remains attractive to developers due to its potential for fine-grained control over resources, improved performance in specific cases, and interoperability with existing systems. However, these benefits come at the cost of increased complexity and potential risks.
To ensure success, explore these risks and provide corresponding mitigation and unmanaged code debugging strategies.
Memory management issues:
Risk: Manual memory management increases the risk of memory-related issues, such as memory leaks. These memory leaks usually appear when the allocated memory is not adequately deallocated, leading to a gradual depletion of memory over time, which may cause the code to run too slowly and even crash the application after a while.
Mitigation: Use smart pointers, minimize the use of raw pointers, and add a comprehensive test for memory management.
Platform dependencies issues:
Risk: Unmanaged code usually relies on platform-specific features or dependencies, leading to compatibility issues across different operating systems or hardware architectures. This may result in portability and general compatibility issues.
Mitigation: Adopting platform-agnostic code practices, isolating platform-specific code, testing and checking the compatibility of the code against the target platforms' specifications.
Security vulnerabilities:
Risk: Unmanaged code tends to be much more vulnerable to buffer overflows and exploits.
Mitigation: Addition of input validation layers, boundary value checking, and regular security assessments for the code.
Concurrency and thread safety:
Risk: The lack of built-in support for managed concurrency of the unmanaged code can lead to race conditions, deadlocks, and other synchronization issues. Without a proper synchronization mechanism, multiple threads accessing shared resources may interfere with each other, resulting in unpredictable behavior and even data corruption.
Mitigation: Implementation of synchronization mechanisms, thread-safe data structures, and comprehensive testing for thread safety.
Loose pointers:
Risk: A risk related to unmanaged code can be the loose pointers, which pointers either point to locations with deallocated memory or invalid points in general.
Mitigation: Nullification of pointers after memory deallocation or using memory debugging tools.
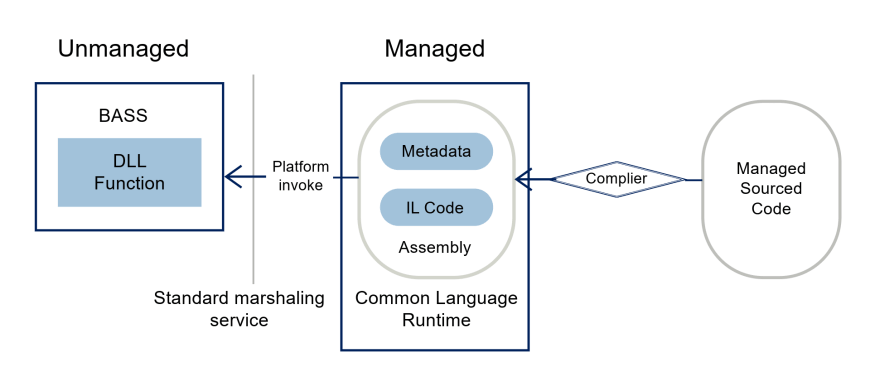
Image 2: Difference between Managed and Unmanaged Code
4. Performance Optimization in Managed and Unmanaged Code
4.1. Things to consider in managed code performance optimization:
Crafting performant managed code involves a combination of strategic choices and targeted optimizations. At its core lies the selection of efficient data structures and algorithms that align perfectly with the application's requirements. Doing so ensures that data manipulation and processing occur smoothly, without unnecessary code complexity.
-
Memory allocation
Furthermore, minimizing memory allocation is crucial for maintaining a smooth-running application. Techniques like object pooling, where frequently used objects are pre-allocated and reused, can significantly reduce the time and resources spent on frequent memory allocation and deallocation cycles. Additionally, whenever possible, utilizing stack allocation for short-lived data can further optimize memory usage.
-
Bottlenecks and performance
Identifying and addressing bottlenecks is another key aspect of performance optimization. Bottlenecks are points in your code where processing slows down, hindering overall performance. By pinpointing these areas through profiling tools, developers can focus their optimization efforts on the most impactful sections of the code.
-
Further optimization of managed code
Finally, taking advantage of the compiler optimizations offered by managed code environments adds another layer of efficiency. These optimizations, often enabled by default, can analyze and streamline your code, resulting in faster execution. By combining these strategies, developers can create well-performing managed code applications that deliver a smooth and responsive user experience.
4.2. Things to consider in unmanaged code performance optimization process:
As previously stated, unmanaged code introduces a different set of challenges for memory management. Unlike managed environments, developers take complete control over memory allocation and deallocation. This necessitates careful planning to avoid potential performance bottlenecks.
-
Manual memory management with unmanaged code
One key strategy involves manual management of memory, which allows for fine-grained control over how memory is allocated and utilized. This empowers developers to choose data structures and memory allocation methods that are optimized for the specific use case. For instance, leveraging platform-specific structures can sometimes offer more efficient memory usage compared to generic structures.
-
Memory allocation and deallocation strategies
Furthermore, minimizing unnecessary memory allocations and deallocations is crucial. Techniques like pre-allocating and reusing memory through object pooling significantly reduce the overhead associated with frequent memory operations. Additionally, loop optimization and memory layout optimization can further improve performance by streamlining how data is accessed and processed in memory. Finally, utilizing compiler optimizations available in specific development environments can often provide additional performance gains by analyzing and restructuring the code for better efficiency.
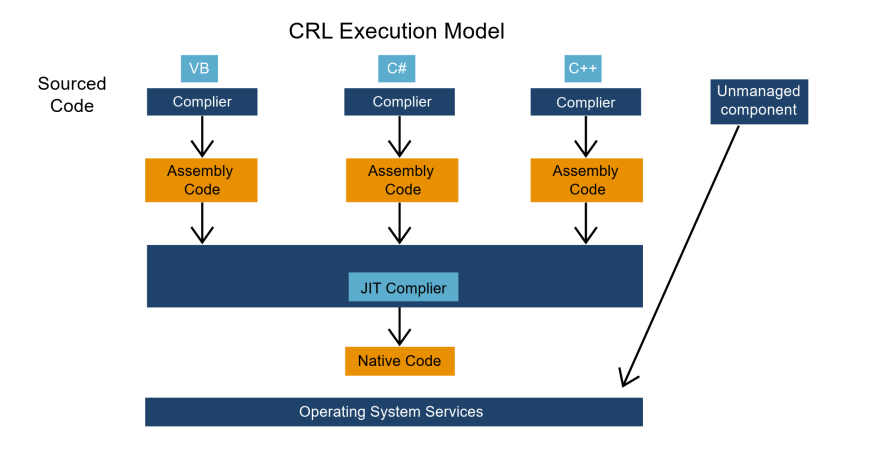
Image 3: CRL Execution Model
5. Testing Strategies for Unmanaged Code
Beyond code development, ensuring the quality and robustness of applications built with managed and unmanaged code in the .NET environment requires a diverse testing strategy. Use this table to identify and employ the testing techniques that will support you in thoroughly scrutinizing different aspects of your application.
|
Techniques |
Purpose |
Approach |
|
API testing |
Validate functionality and security of exposed APIs. |
Develop test cases, validate responses, and use API testing tools. |
|
Fuzz Automation testing |
Inject invalid inputs or corrupted data to discover vulnerabilities. |
Use fuzz testing tools to generate and execute test cases automatically. |
|
Manual testing
|
Validate memory management and system interactions. |
Develop manual test cases, use debugging tools, and analyze system behavior. |
|
Integration testing
|
Validate interaction with other components. |
Test data exchange, function calls, and cross-platform compatibility. |
|
Performance testing
|
Evaluate speed, scalability, and resource utilization. |
Develop performance test cases, measure metrics, and analyze performance. |
6. Frequently Asked Questions and Best Practices for Testing Managed and Unmanaged Code
1. How can I ensure I'm testing all aspects of my application, including managed and unmanaged code?
Answer: Develop a strong set of test cases that encompass various aspects of your application's functionality, including edge cases, error scenarios, and boundary conditions. This ensures proper behavior under diverse situations. Test both normal and exceptional behavior to verify the application's response to various inputs and conditions.
2. What is unit testing, and how does it benefit testing managed and unmanaged code?
Answer: Unit testing involves validating individual components or modules within your code, regardless of whether it's managed or unmanaged. Unit tests help verify the correctness of specific functions or methods and detect regressions when code changes are made.
3. How do I test how my application components interact?
Answer: Perform integration testing to verify seamless collaboration between different components within your application. This helps identify and address potential issues arising from component interactions, ensuring integrated parts of the system work together effectively.
4. Can I automate some of the testing processes to improve efficiency?
Answer: Leverage automated testing frameworks and tools to streamline the testing process and increase test coverage. Automation reduces the effort required to run tests repeatedly and consistently, enabling faster feedback on code changes and improving overall efficiency.
5. How do I test the performance and scalability of my application, especially when using both managed and unmanaged code?
Answer: Conduct performance testing to evaluate the performance and scalability of your code. This involves measuring key metrics like response times, throughput, and resource utilization. By identifying performance bottlenecks through this testing, you can optimize your code for both managed and unmanaged sections.
6. Is security testing important for both managed and unmanaged code?
Answer: Integrating security testing into your development process is crucial for identifying and mitigating potential security vulnerabilities in both managed and unmanaged code. This involves utilizing static analysis, dynamic analysis, and penetration testing to detect and address security issues early in the development lifecycle, ultimately ensuring a more secure application.
7. How do I maintain transparency and collaboration within my team when testing both managed and unmanaged code?
Answer: Documenting test cases, test results, and any identified issues or bugs serves several purposes. It ensures traceability, facilitating collaboration and knowledge sharing among team members. Additionally, clear documentation enables efficient debugging and troubleshooting when issues arise.
7. Mastering the Balancing Act: Managed vs. Unmanaged Code
Choosing between managed and unmanaged code involves navigating a spectrum of possibilities, challenges, and considerations for developers. While managed code offers the convenience of automatic memory management and platform abstraction, it comes with overheads such as garbage collection and limited control over system resources. On the other hand, unmanaged code provides greater control and performance optimization opportunities but requires meticulous attention to memory management and platform dependencies.
To mitigate the risks associated with managed and unmanaged code, developers must adhere to best practices and adopt robust testing methodologies. Thorough testing, including unit testing, integration testing, and performance testing, is essential to ensure the reliability, security, and performance of software applications. Furthermore, automated testing frameworks streamline the process and boost coverage, fostering faster feedback and enabling continuous development practices.
By embracing these practices, developers can navigate the complexities of managing and testing both managed and unmanaged code effectively, delivering high-quality software that meets the demands of today's software development environments. As we upskill, the principles outlined here serve as a timeless guide, seeking to empower developers to deliver exceptional solutions to end-users.

